Care should be taken when designing your cloud to take into consideration not only the performance
of your disk arrays but also the bandwidth available to move that traffic between the switch fabric and
the array interfaces.
CloudStack Networking For Storage
The first thing to understand is the process of provisioning primary storage. When you create a primary
storage pool for any given cluster, the CloudStack management server tells each hosts’ hypervisor to
mount the NFS share or (iSCSI LUN). The storage pool will be presented within the hypervisor as a
datastore (VMware), storage repository (XenServer/XCP) or a mount point (KVM), the important point is
that it is the hypervisor itself that communicates with the primary storage, the CloudStack management
server only communicates with the host hypervisor. Now, all hypervisors communicate with the outside
world via some kind of management interface – think VMKernel port on ESXi or ‘Management Interface’ on
XenServer. As the CloudStack management server needs to communicate with the hypervisor in the host,
this management interface must be on the CloudStack ‘management’ or ‘private’ network. There may be
other interfaces configured on your host carrying guest and public traffic to/from VMs within the hosts
but the hypervisor itself doesn’t/can’t communicate over these interfaces.
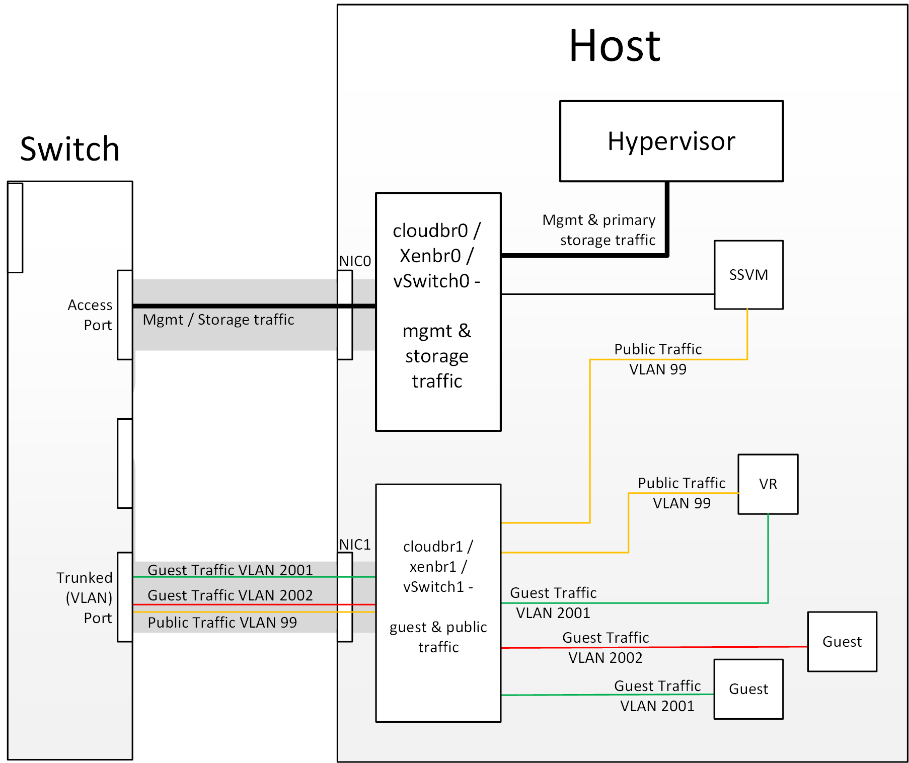 Figure 1: Hypervisor communications
Figure 1: Hypervisor communications
Separating Primary Storage traffic
For those from a pure virtualisation background, the concept of creating a specific interface for storage
traffic will not be new; it has long been best practice for iSCSI traffic to have a dedicated switch
fabric to avoid any latency or contention issues.
Sometimes in the cloud(Stack) world we forget that we are simply orchestrating processes that the
hypervisors already carry out and that many ‘normal’ hypervisor configurations still apply.
The logical reasoning which explains how this splitting of traffic works is as follows:
- If you want an additional interface over which the hypervisor can communicate (excluding teamed or bonded interfaces) you need to give it an IP address.
- The mechanism to create an additional interface that the hypervisor can use is to create an additional management interface
- So that the hypervisor can differentiate between the management interfaces they have to be in different (non-overlapping) subnets
- In order for the ‘primary storage’ management interface to communicate with the primary storage, the interfaces on the primary storage arrays must be in the same CIDR as the ‘primary storage’ management interface.
- Therefore the primary storage must be in a different subnet to the management network
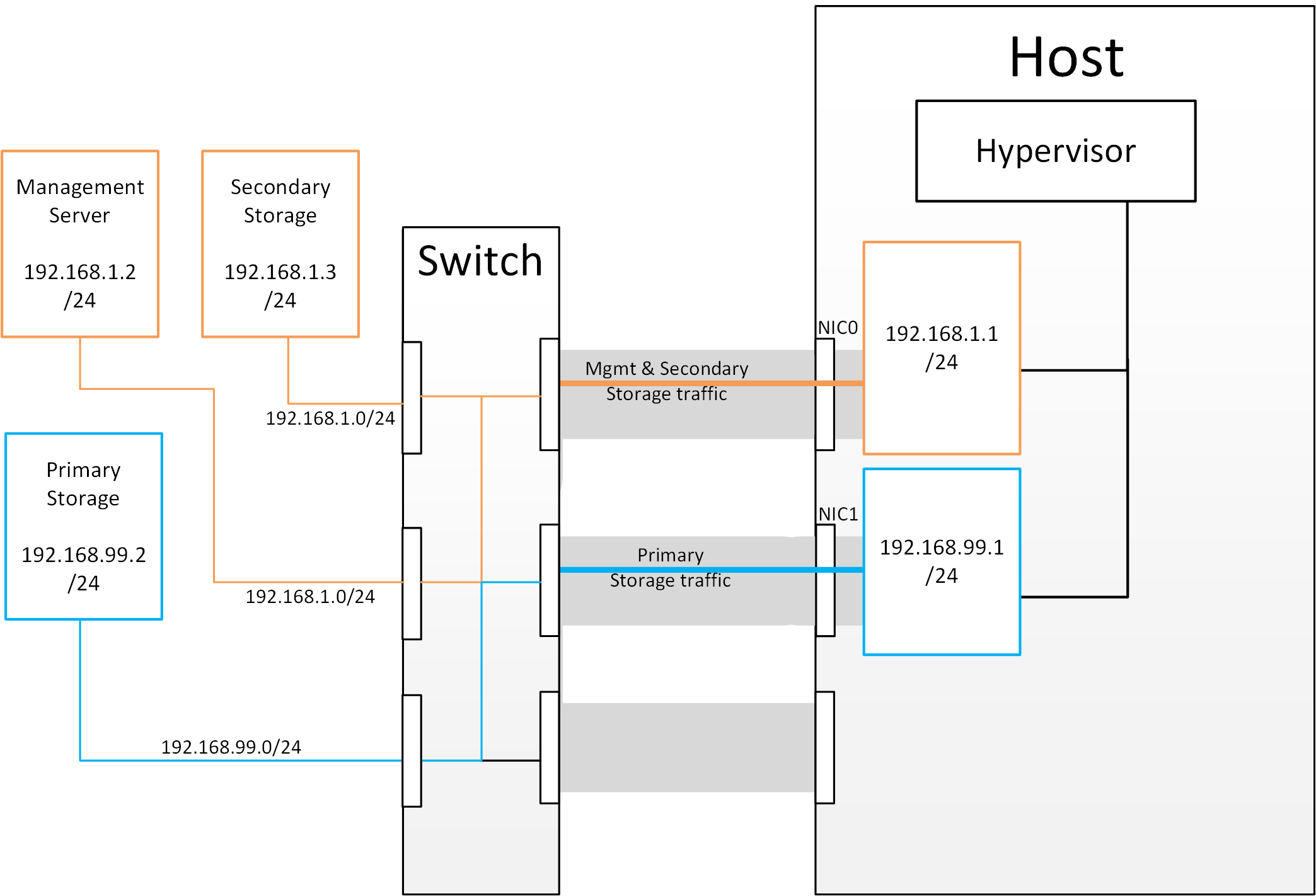 Figure 2: Subnetting of Storage Traffic
Figure 2: Subnetting of Storage Traffic
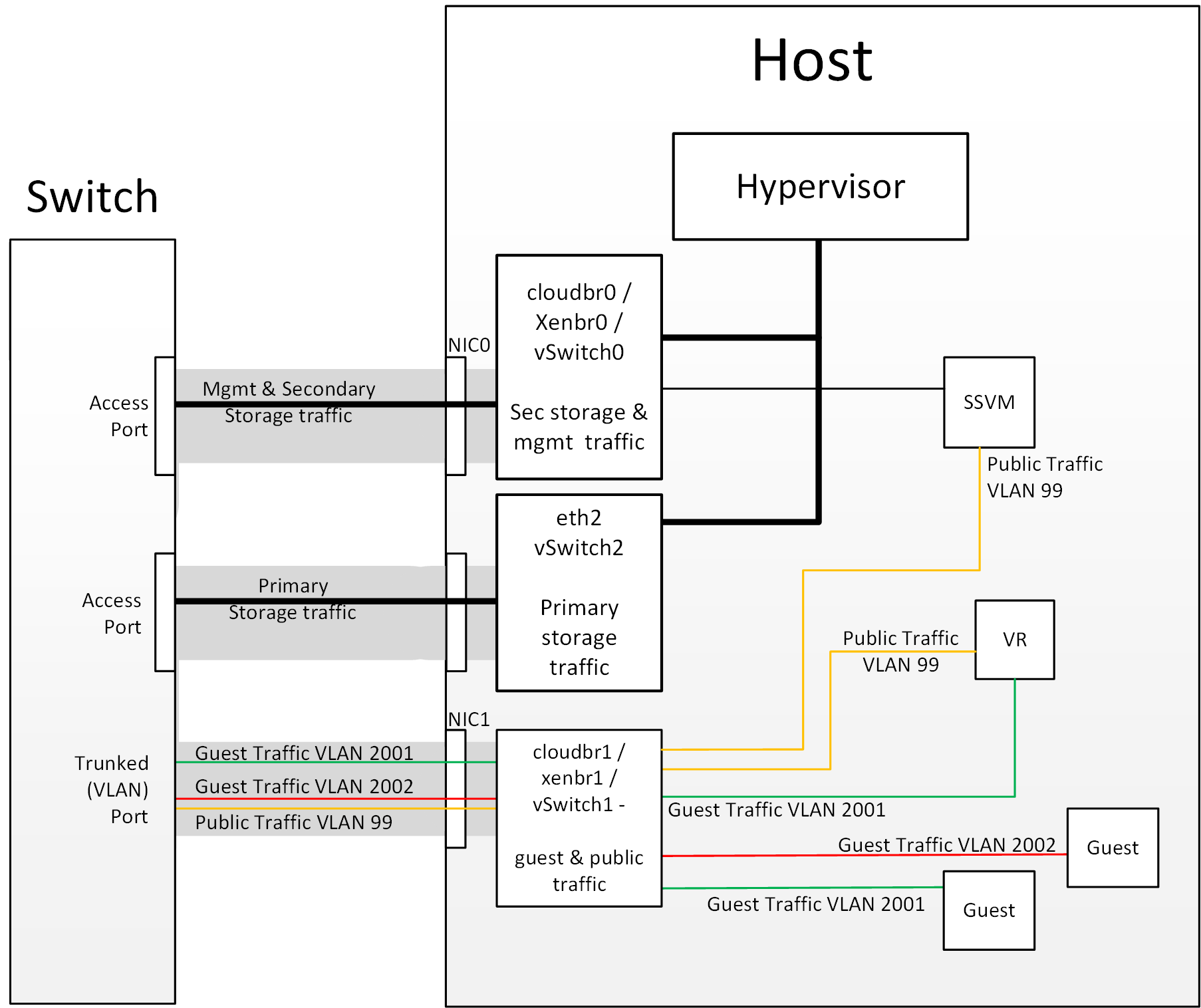 Figure 3: Hypervisor Communications with Separated Storage Traffic
Figure 3: Hypervisor Communications with Separated Storage Traffic
Other Primary Storage Types
If you are using PreSetup or SharedMountPoints to connect to IP based storage then the same principles
apply; if the primary storage and ‘primary storage interface’ are in a different subnet to the ‘management
subnet’ then the hypervisor will use the ‘primary storage interface’ to communicate with the primary
storage.